The Distributed Data Model

Regardless of how tidy and organized your Grasshopper script is, it becomes increasingly challenging to manage the growing complexity, especially when your model has many different modelling parts.
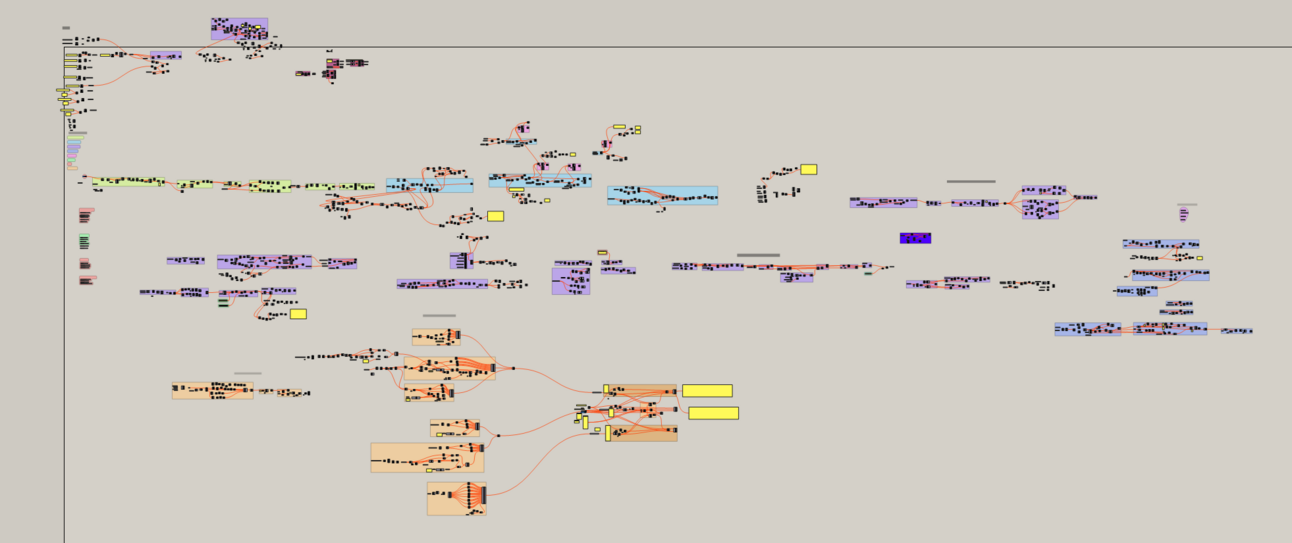
Even with a somewhat tidy script, the sheer number of operations can quickly render it barely readable and difficult to manage. In any large project, the expansion of Grasshopper scripts is a natural progression and quite unavoidable.
However, there is a solution—a workaround that involves using several smaller Rhino files and Grasshopper scripts instead of a single gigantic file. This approach known as the distributed data model, is one of the most effective ways of working with large-scale projects.
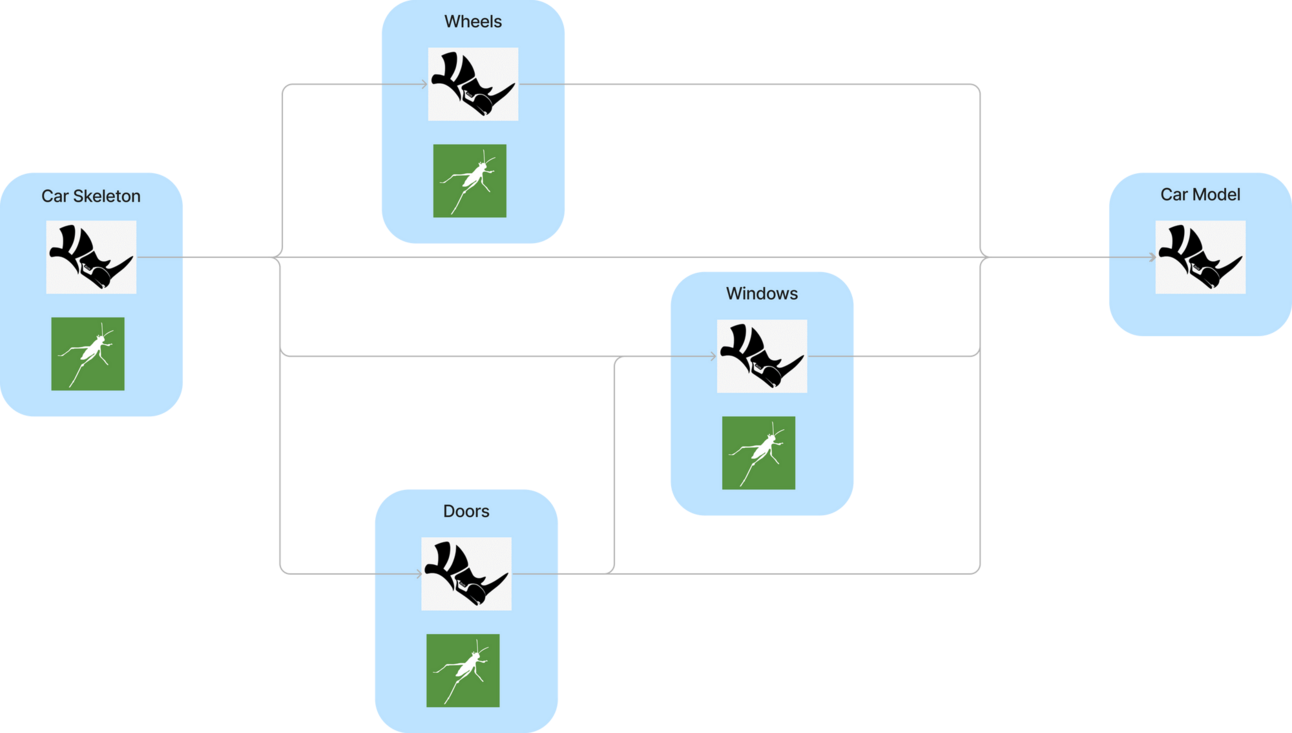
The distributed data model is similar to the “small functions” best practice from the programming world. Where many smaller functions are preferred over a single large function. The theory of this is that smaller functions are easier to read, manage and edit than larger functions. The same can be said for Grasshopper scripts too.
Not to mention, this data model utilises Rhino files as the medium for transferring data between these smaller Grasshopper scripts. This approach enhances script organization and improves performance, as it reduces the amount of data that Rhino needs to handle at any given time. So, while the overall amount of data has increased, the data at any given time is lower.
Let’s walk through the other benefits of the distributed data model.
The Single Responsibility Principle
The distributed data model in Grasshopper adheres to another programming best practice known as the single responsibility principle, which represents the 'S' in the SOLID Principles of good programming.
When working with a multi-faceted model that has a lot of complex parts, it's easy to become overwhelmed by the number of operations involved. The single responsibility principle is then the idea of separating out all these parts into their own function/script, making it easier to manage.
In Grasshopper, this means we should dedicate a Grasshopper script to each part of the model.
Collaboration
Another significant benefit of splitting the modelling process into multiple Grasshopper scripts is that you can collaborate with others on the same model. This distributed approach lets multiple people work simultaneously on different parts of the model without conflicts or file clashes.
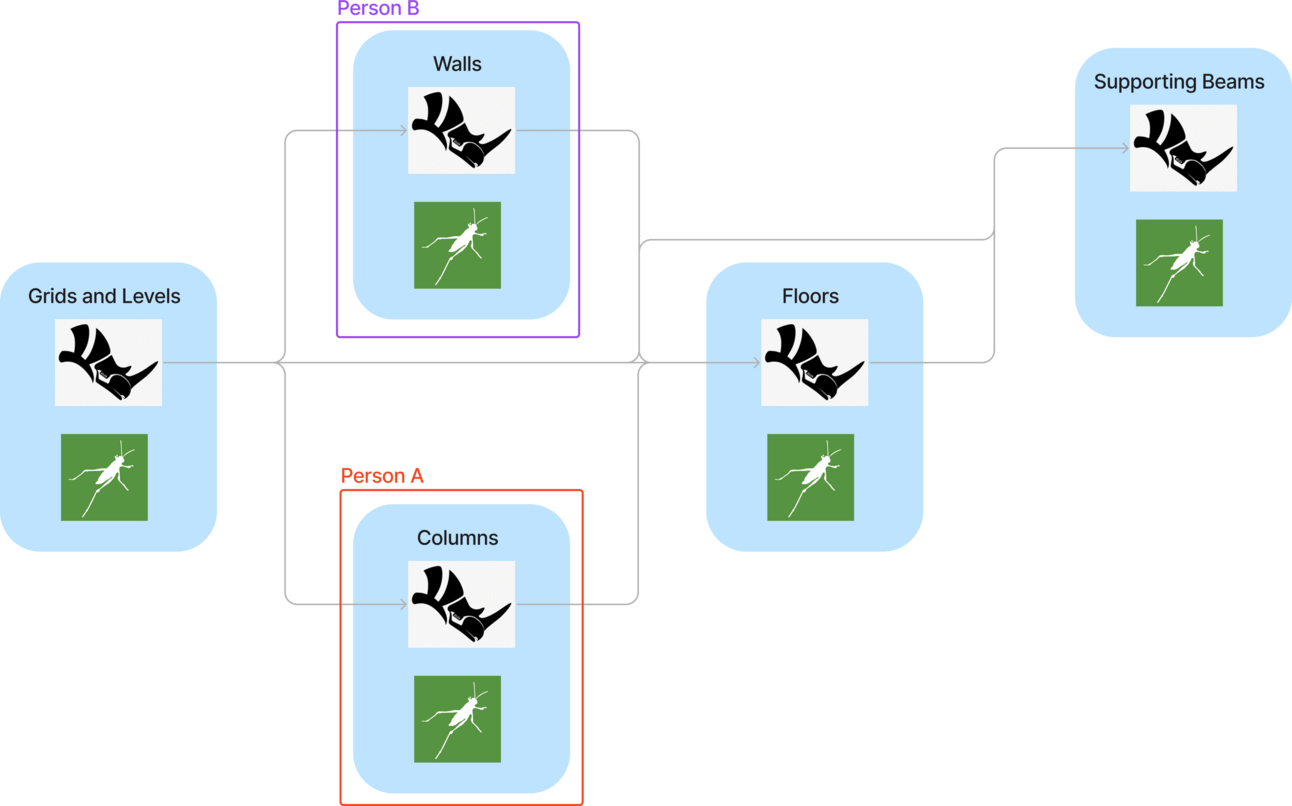
Additionally, from a project risk perspective, having multiple people working on the model offers several advantages over relying solely on a single person. Distributing the workload helps to avoid risks by diffusing responsibility and promoting internal checks.
A Bespoke System
I am a big fan of the flexibility that Grasshopper offers, but I believe that to fully harness its potential, introducing some structure is essential. This is where the distributed data model comes into play, providing much-needed structure.
By breaking down a big complex script into smaller, more manageable scripts, the distributed data model lets you plan and structure the interactions, making the entire process more robust.
It gives rise to a unique Grasshopper/Rhino system tailored specifically to your project and modelling process. I’ll dive deeper into this data model later because there is a lot more to cover. For now, here are some tools to get you started.
Tools
As Rhino is the 'input' and 'output' for the various Grasshopper scripts, utilizing 'baking' and ‘layer reading’ type components can greatly simplify the process.
With that in mind, I recommend two tools that specifically focus on the data interaction between Grasshopper and Rhino. But, there are many other tools available on the internet that can help with this.
Elefront
Elefront is a plugin focusing on the data interaction between Grasshopper and Rhino. Letting you seamlessly bake to Rhino, read from Rhino layers and more.
In fact, this plugin was used in a significant showcase for the distributed data model, when the architect company, Zaha Hadid, used this data model to design the Morpheus Hotel in Macau. You can read more about it here.
Elefront is one of the most useful plugins in the distributed data model because it lets you programmatically read and write to Rhino.
Rhino Work-sessions
“Work-sessions” is a feature that comes natively with Rhino 7 (Windows). A work session allows you to work with multiple Rhino files in one Rhino instance. it essentially lets you “attach” multiple Rhino files onto an active one.

This is useful because you only need to “attach” the relevant Rhino files for the right Grasshopper script. You can also save work session files (.rws) which remember all the Rhino files you had opened before. To access the work session panel, just type “Worksession” into the command bar in Rhino.
Final Thoughts
The distributed data model in Grasshopper presents a compelling solution to the challenges posed by using a single large Grasshopper and Rhino file for complex multi-faceted models.
By following programming best practices like the single responsibility principle, it breaks down the large modelling task into smaller, more manageable tasks, bringing structure and collaboration into the mix. Additionally, the use of smaller Rhino and Grasshopper files also enhances the performance and robustness of the entire modelling process.
There is much more to discuss regarding the distributed data model. I firmly believe that it is one of the most critical methodologies when it comes to using Grasshopper and working on complex models within a team. This article may have been somewhat abstract, as its primary intention was to explain the basic principles of the distributed data model. In the future, I plan to explore and write about the more practical aspects of this model.
So stay tuned and thanks for reading
Braden.